CLIP-Topic: Identifying Themes in Large Image Collections
Heritage institutions hold vast collections of digital images that remain difficult to search or interpret. CLIP-Topic shows how multimodal AI can be used to surface…
Dec 1, 2025
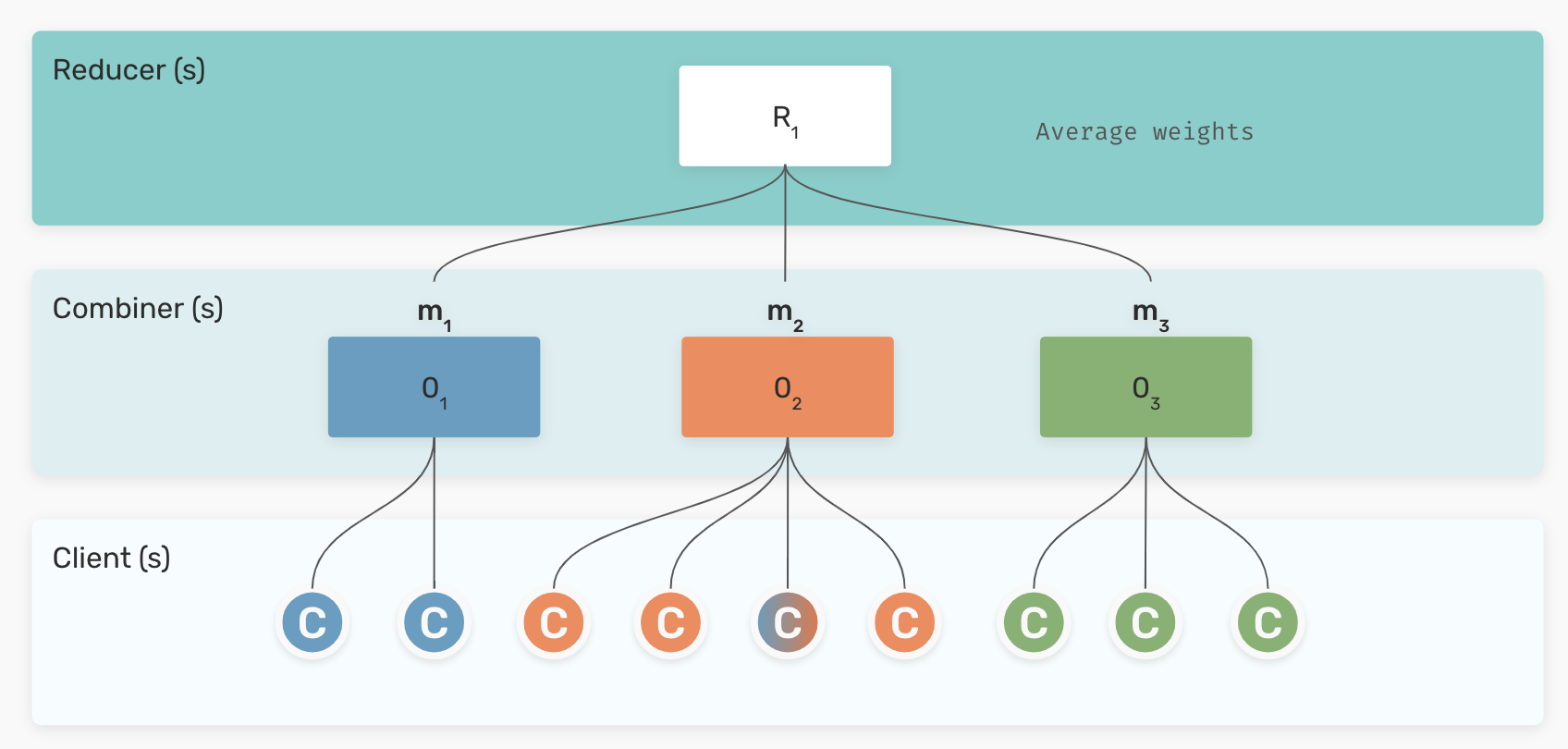
We trained a bilingual Swedish-Norwegian ELECTRA language model in a federated setup, showcasing LM training when various…