Finding Comics in Swedish Newspapers: A Computer Vision Pilot at KBLab
An exploratory internship project testing how computer vision can help identify candidate comic pages in digitised Swedish newspapers.
Jul 3, 2026
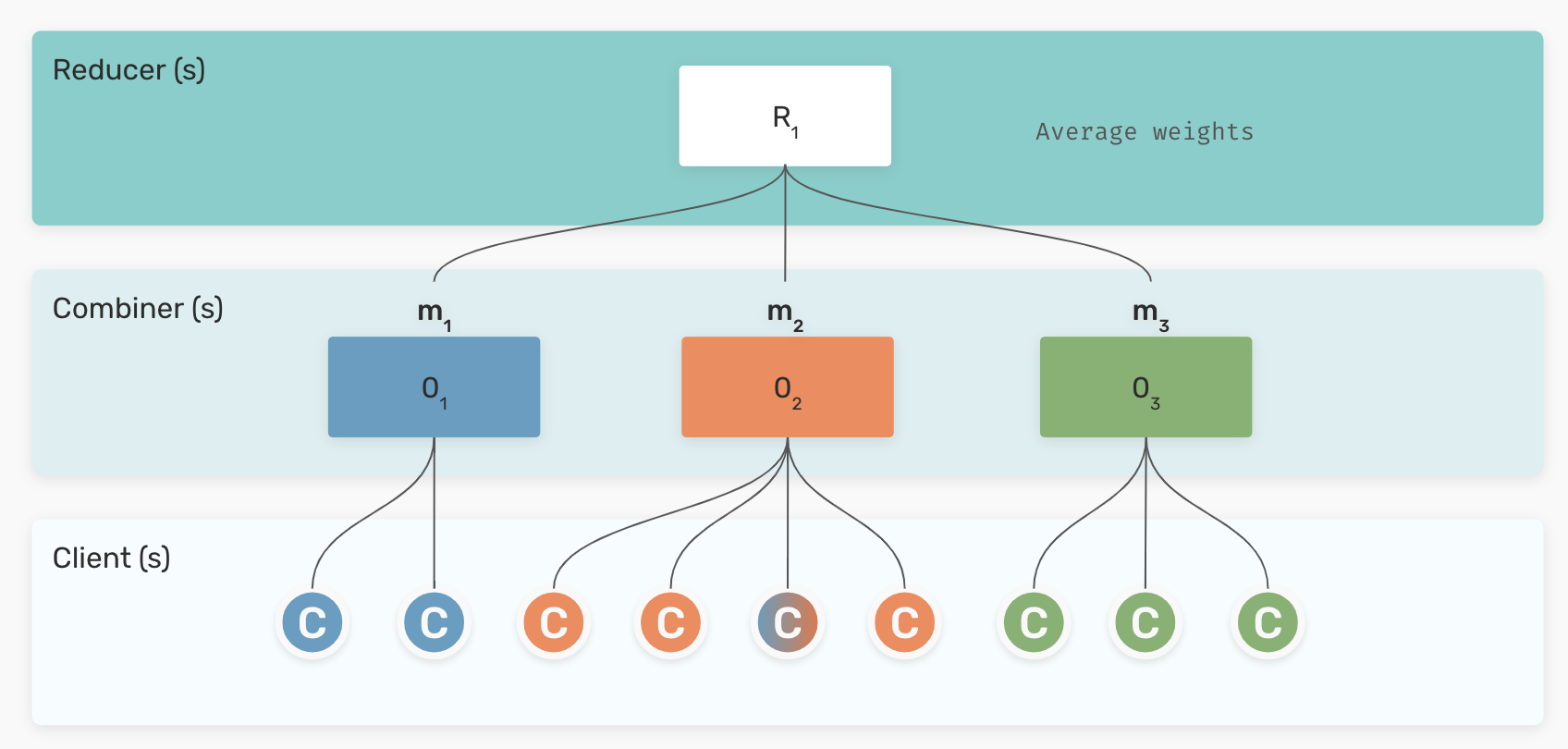
We trained a bilingual Swedish-Norwegian ELECTRA language model in a federated setup, showcasing LM training when various…