The emergence of transformer-based language models has significantly enhanced the potential for machine learning to be used for extracting meaning from large volumes of text. Yet this potential has hitherto been limited to the select few with the requisite knowledge in data science. To the vast majority without prior experience of programming in Python, the promise of cutting-edge language processing from a BERT model remains just that—a distant promise.
However, this has now changed with the development of BERTopic. Recent work by the Dutch data scientist, Maarten Grootendorst makes it possible to harness the impressive performance of BERT language models without first needing to become an expert in data science. More specifically, it enables the sophisticated and flexible NLP capacities of a BERT model to serve as the basis for a more accessible form of topic modeling. By offering a new and simpler way of using KBLab’s language models, BERTopic brings a cutting-edge yet previously technically challenging method within reach of a broader range of researchers and other users working with Swedish material.
In this post, we provide a brief introduction to using BERTopic for topic modeling with Swedish text data. We explain how BERTopic harnesses KBLab’s models to produce state-of-the-art topic models, and we outline some tips on how to get started. If you’re interested in finding out more about this particular method, or about topic modeling in general, check out the links at the bottom of the page!
What is topic modeling and why might it be helpful for researchers?
Topic modeling is a quantitative method for text analysis that allows researchers to gain insights on large text corpora without manually going through all the data themselves. The principal idea is to find a number of major topics in the collection and to be able to retrieve documents that are relevant for these topics.
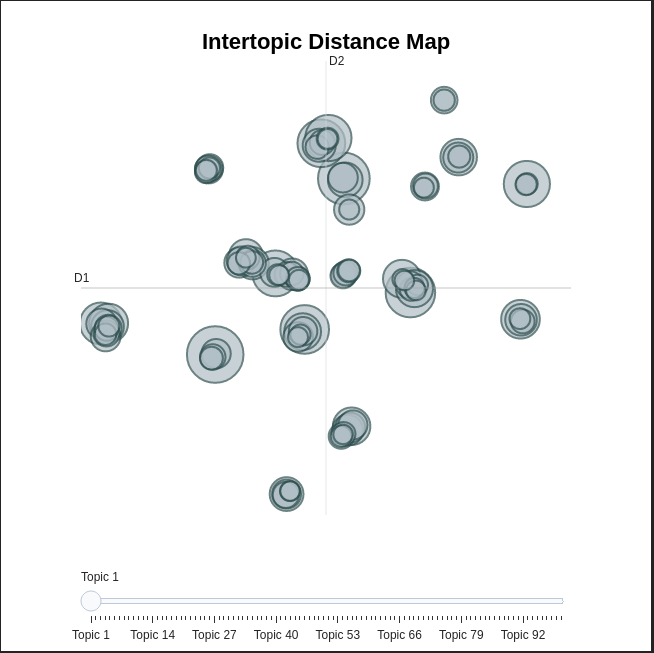
The output of a topic model is a list of topics represented by words that define them. It is possible to visualize the topics in charts to see their size and distance to each other (see Figure 1).
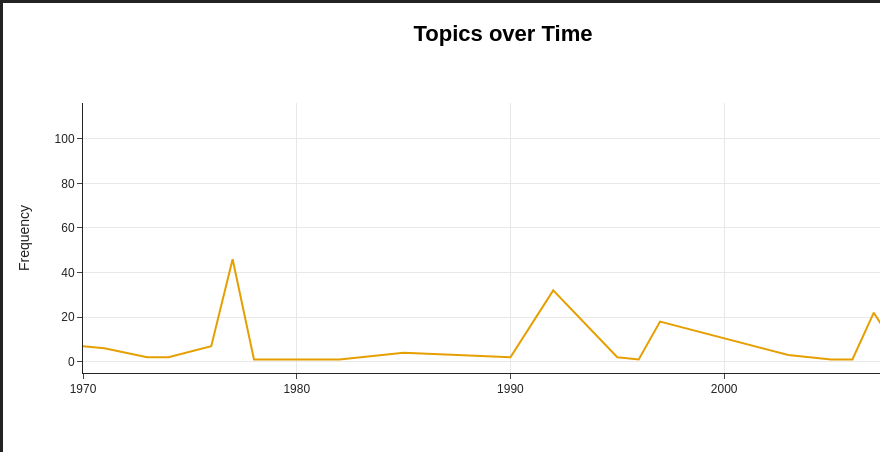
Topic models can be used in many ways, for example to follow the development of a concept over time or to analyze subtopics of a given issue (see Figure 2 and Figure 3). The main insight is in utilizing data mining algorithms to make vast amounts of data searchable—and thus legible—according to the particular themes of which it is comprised.
What’s new with BERTopic and how does it make the method more accessible?
BERTopic is a new topic modeling tool that builds on powerful neural networks. At the base there is a model called sentence-BERT, which can be considered an all-purpose language model that has some understanding of the meaning of a sentence or paragraph. The documents are grouped into clusters and then some words are extracted from each cluster to label the topic.
The main advantage of BERTopic over traditional topic models is that there is next to no pre-processing of the documents required prior to modeling: the pre-trained transformer model, sentence-BERT, takes care of identifying the meaningful parts of the text, which means that we don’t need to do it by hand. On top of that, the process is highly automated, so there are relatively few operative decisions that can influence the final result and that need to be accounted for.
What do you need to do to get started with this method?
To build a BERTopic model you need to have a collection of relatively short documents, for example paragraphs or abstracts. While you don’t need to be an expert, you do need some experience with Python programming, since you need to be able to load your documents into Python to run the modeling on them. If you are planning to use the method on Swedish data, then you may want to use the sentence transformer model we have released, which can be found on KBLab’s HuggingFace page (see link below).
There are excellent tutorials available via the BERTopic repository on Github (link below), which provide the best starting point for testing out the method.
What are the computational requirements of this approach?
The powerful language model that BERTopic is based on needs to run on a GPU, which not everyone has at their disposal. There are two possible solutions if you do not have access to a GPU at your institution: either you can run BERTopic with less computation-intensive embedding models like Flair, spaCy or Gensim, or you can use Google Colab to have temporary free access to a GPU.
Both options have pros and cons. Using a lighter model that runs on CPU means giving up some of the complex language understanding of a transformer model: BERT and similar models have consistently proven to be superior to other methods in many NLP tasks, and a BERTopic without an underlying BERT would be falling short of its full potential. Using Google Colab, on the other hand, means that you need to have a Google account, you need to have permission to load your documents online and you might not get enough GPU memory and/or time for your modelling needs. But having said that, experimenting with this latter option would certainly be a good place to start!

Links about BERTopic:
Tutorials on GitHub: https://github.com/MaartenGr/BERTopic
Complete documentation: https://maartengr.github.io/BERTopic/
KBLab’s sentence BERT for Swedish: https://huggingface.co/KBLab/sentence-bert-swedish-cased
Google Colab: https://colab.research.google.com/
Further reading on topic modeling as a research method:
“Topic Modeling with BERT,” Medium article by Maarten Grootendorst: https://towardsdatascience.com/topic-modeling-with-bert-779f7db187e6
“Interactive Topic Modeling with BERT,” Medium article by Maarten Grootendorst https://towardsdatascience.com/interactive-topic-modeling-with-bertopic-1ea55e7d73d8
“Probabilistic Topic Models,” David M. Blei article: https://www.cs.columbia.edu/~blei/papers/Blei2012.pdf
“The Digital Humanities Contribution to Topic Modeling”, Journal of Digital Humanities special edition: http://journalofdigitalhumanities.org/2-1/
“Topic Modeling: What Humanists Actually Do With It,” University of California blog post by Teddy Roland: https://digitalhumanities.berkeley.edu/blog/16/07/14/topic-modeling-what-humanists-actually-do-it-guest-post-teddy-roland-university
Citation
@online{fano2022,
author = {Fano, Elena and Haffenden, Chris},
title = {BERTopic for {Swedish:} {Topic} Modeling Made Easier via
{KB-BERT}},
date = {2022-06-14},
url = {https://kb-labb.github.io/posts/2022-06-14-bertopic/},
langid = {en}
}