The Riksdag is Sweden’s legislature. The 349 members of the Riksdag regularly gather to debate in the Chamber of the Parliament House. These debates are recorded and published to the Riksdag’s Web TV. For the past 20 years the Riksdag’s media recordings have been enriched with further metadata, including tags for the start and the duration of each speech, along with their corresponding transcripts. Speaker lists are added to each debate, allowing viewers to navigate and jump between speeches easier 1. This metadata also allows linking members of parliament and ministers with the debates they have participated in.

The Chamber.
Photo: Melker Dahlstrand /The Swedish Parliament
Happening upon these recordings and seeing them linked to such rich metadata, we were curious to learn if the Riksdag had planned to make them available through its open data platform and APIs. We e-mailed them to inquire whether an audio/media file API was in the plans, to which they responded that such an API in fact already did and does exist, although they had yet to settle on a good way of communicating this service to the public.
Part of our work here at KBLab involves training Swedish Automatic Speech Recognition (ASR) models capable of transcribing speech to text. We release these models freely and openly, see for example our wav2vec2-large-voxrex-swedish model (Malmsten et al. 2022). Here, audio datasets with annotated transcriptions play an especially important part for quality. Unfortunately such datasets are hard to come by for Swedish. The combined total of current available datasets with annotated transcriptions number somewhere in the hundreds of hours.
Decades of debates from the Riksdag present a golden opportunity to increase this quantity by a factor of tenfold or more. The wealth of dialects and accents, along with the breadth of metadata covering electoral districts, birth year and the gender of members of parliament may serve to not only improve ASR systems, but also to enable research on the weaknesses and biases of both current and future models.
However, in order to get the speeches and transcripts properly aligned so they can be brought to a suitable and workable format, we first need to ensure the region of audio within a debate representing a speech actually matches the written transcript. Additionally no other speakers should ideally be present in this window.
The importance of metadata
When assessing the quality of the available metadata from debates, we found most of the material from 2012 and forward was generally accurate and of high quality. However, the required degree of precision of metadata always depends on one’s use case. And in our case it was important that only one speaker – the one making the speech – be present in the indicated window. With this in mind, it soon became evident that a certain level of adjustment of the existing metadata was required. Illustrating this with an example below, we see that the Riksdag’s metadata (right video) tends to include parts where the speaker of the house talks. The left video shows the automatically generated metadata from the method we developed for locating and segmenting speeches. We employed speaker diarization to more precisely pinpoint when a speaker starts and stops speaking.
Both videos below will update at the same time when pressing “Next debate”/“Previous debate”. The speeches are set to begin and end playing at the “start” and “end” of both metadata sources. Play them one after another to see how they compare in terms of speech segmentation.
Modern Riksdag metadata, such as the debate above, serve as a good benchmark against which we can evaluate our fully automated method. Should our method – using only official transcripts and audio – be able to roughly match the segmentation quality of these more recent debates, we can be reasonably certain it can also fare well when applied on older materials.
Below we display speeches from 10 sampled debates from before 2012-01-01 – a period where metadata quality tends to be shakier. The first and the second debate, “Regeringens skärpning av migrationspolitiken” and “Kvalitet i förskolan m.m.”, contain large errors in the Riksdag’s metadata when it comes to start and end times. It appears the metadata in these debates have shifted to be off by an entire speech. In addition to the above, we found mismatches between the indicated names of the speakers in text form and in the internal id-system that the Riksdag use to identify members of parliament. The more accurate field is intresent_id which lists the id number of the speaker, whereas the text field which lists the name in textual form at times can be misleading.
Likely this is either an off by one error during data entry, a joining of disparate datasets gone wrong, or some post-processing mistake. Since we found the intressent_id field to be reliable, we used the id’s to fetch the names and information of parliament members from a separate data file the Riksdag provides in their open data platform 2.
A higher fraction of the earlier debates from 2003-2006 tend to start and end in the middle of speeches, looking like they may possibly have been automatically edited and spliced based on misaligned metadata. Several of the debates have issues with skips and cuts in the media, possibly resulting from video encoding errors upon conversion to web formats. Hopefully, the full debates are still available in an unedited format somewhere in the Riksdag’s archives.
The Riksdag’s speeches in numbers
The valid downloadable audio files from the Riksdag’s debates have a total duration 6361 hours. There is a metadata field called debateseconds indicating the duration of each debate in seconds. If we sum the claimed duration of debates they amount to 6398 hours.
| Source | Total duration of debates (hours) |
|---|---|
| The Riksdag’s metadata | 6398.4 |
| Audio files | 6361.4 |
How many of those 6360 hours are actually speeches though? According to our speech segmentation, the debate files consist of a total of 5858 hours of speeches. However, when looking at the metadata field duration (for individual speech durations), the total duration of speeches exceed the total duration of the audio files. We note the start and end indications of many speeches overlap with other speeches for metadata prior to 2012.
| Source | Total speech duration of debates |
|---|---|
| The Riksdag’s metadata | 6742.15 |
| Adjusted metadata (KBLab) | 5858.36 |
Our method for finding which debates had associated media files, was to first download the speeches in text form from “Riksdagen’s anföranden”. We then queried the Riksdag’s media API, using the document ids of all those speeches. Out of more than 300000 available speeches from 1993/94 and forward:
- 133130 speeches belonged to debates that had downloadable audio files in the Riksdag’s media API.
- Of the above only 122525 speeches had valid audio files, or were found to be at all present in the audio files.
- After applying additional quality filters 117725 speeches remained. These filters included removing:
- duplicate transcripts attributed to different speakers.
- two or more separate speeches being attributed with the same starting or ending time (indicating the model had failed making a valid prediction).
- debates starting and ending in the middle of speeches.
- sudden jumps/cuts/edits in the audio while a speech was in progress.
- speeches shorter than 25 seconds in duration (the margins of error are narrower for shorter speeches).
Metadata statistics grouped by year
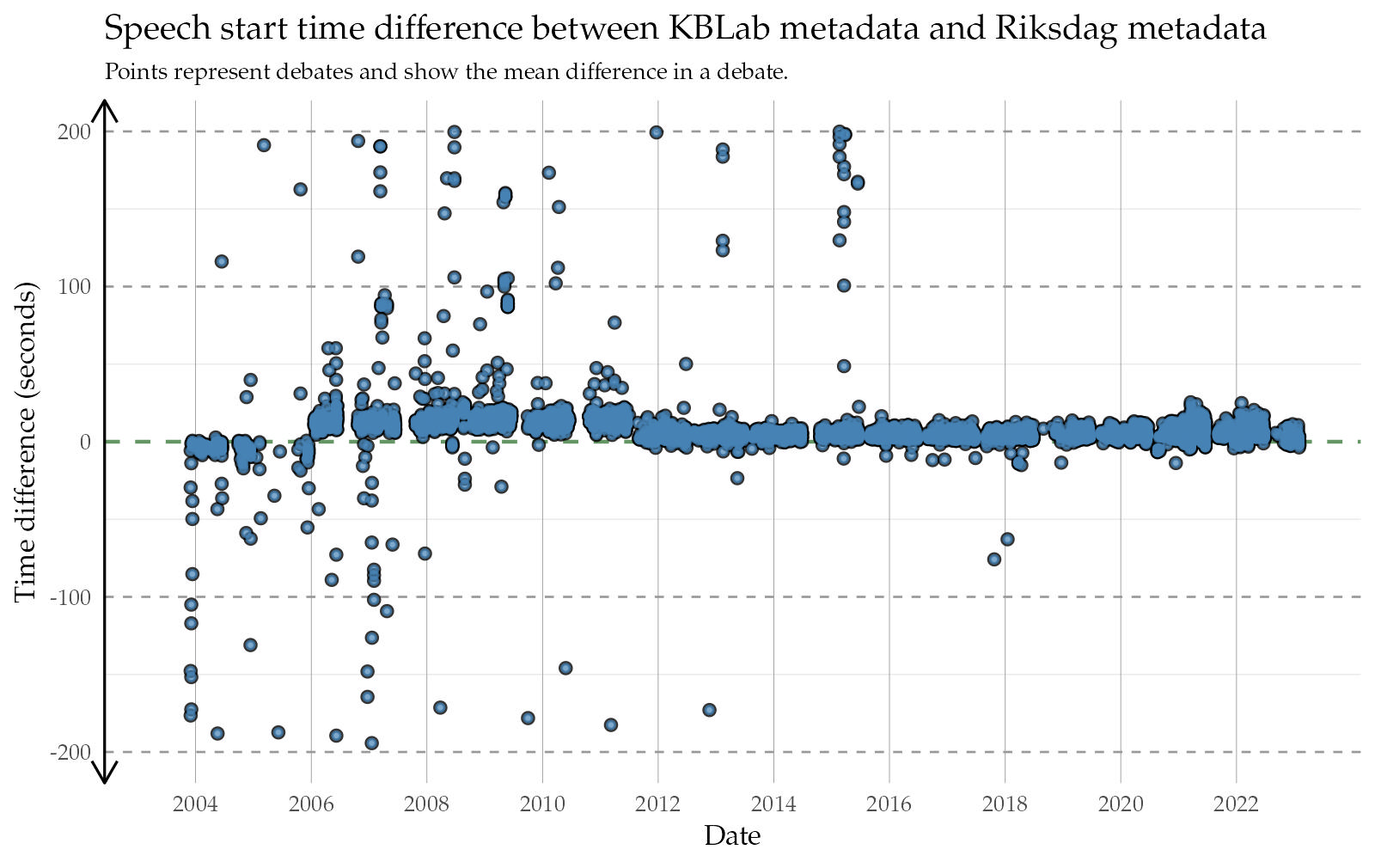
To get an overview of metadata quality over time, we calculated the difference between our adjusted “start” and “end” metadata, and the corresponding metadata from the Riksdag. The table below displays the total hours of audio per year, and the median of the difference between KBLab’s adjusted metadata and the Riksdag’s metadata. Negative start and end difference values reflect that KBLab’s speech starts or ends earlier in the debate audio file, whereas positive difference values reflects KBLab’s speech begins or ends later than the Riksdag’s.
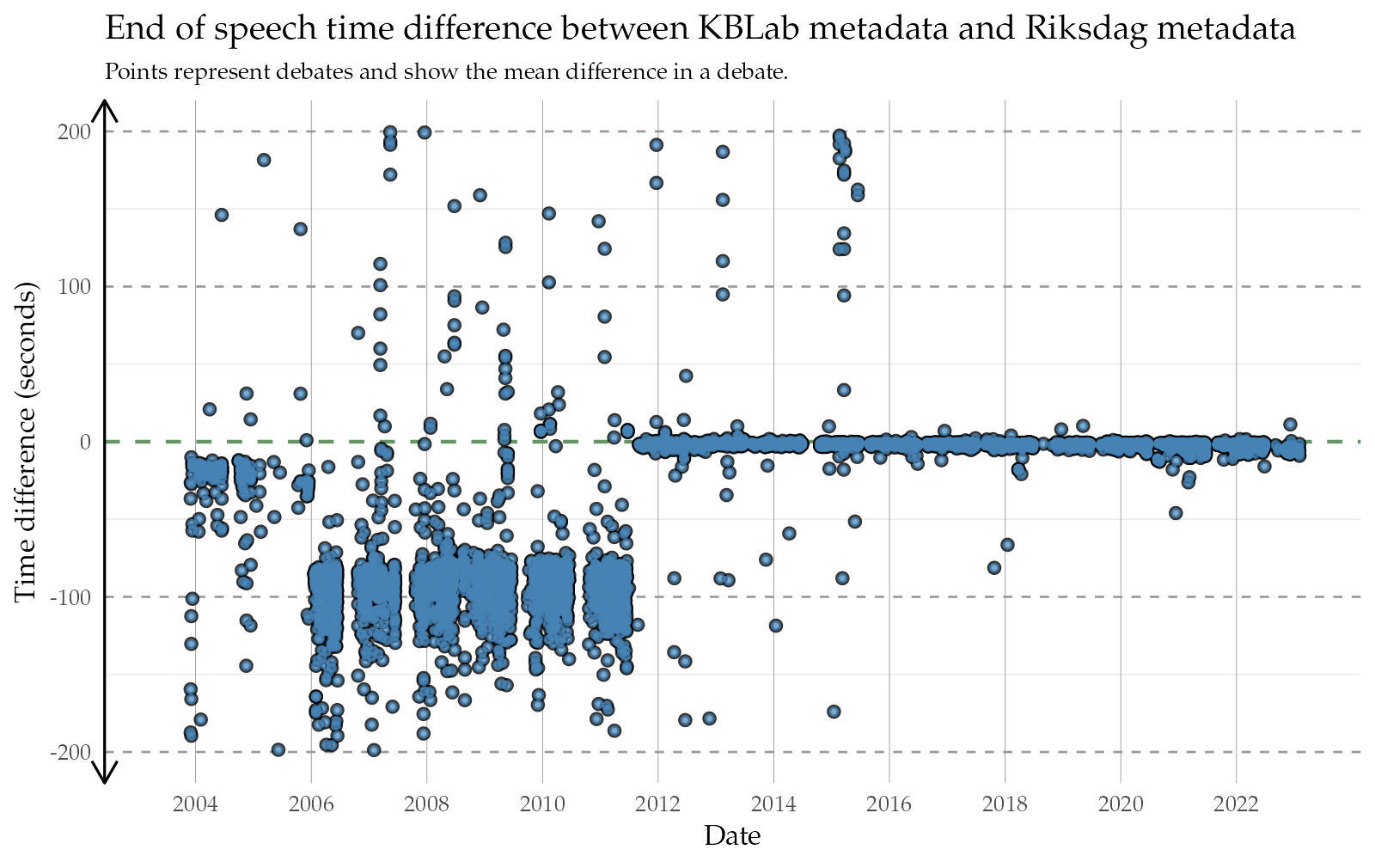
We note how, for several years between 2006 and 2011, the adjusted KBLab metadata places the end of a speech about 85 seconds earlier than the Riksdag. The typical end indication from the Riksdag during these years appears to overshoot the speech by more than a minute. Looking at the same thing in graphical form below, where every point represents the mean difference within an entire debate, we see a systematic pattern of the “end” metadata marker from the Riksdag overshooting the end of speeches (Figure 1 (b)). In contrast, most of the “start” metadata markings (Figure 1 (a)) are more accurate. Perhaps this was a conscious choice, as capturing the start of a speech might have been deemed more important than spending a lot of time and resources capturing the exact ending of the speech.
Most and least intelligible speakers
After adjusting the metadata, we used the new metadata to split the debate audio file in to speech segments. These speech files were machine transcribed and evaluated against the official transcript using the BLEU score. High BLEU score generally indicate there’s a high correspondence or overlap between the output of the machine transcription and the official transcript.
In the table below, we display the 30 speakers with the lowest mean BLEU score, among those speakers with more than \(5\) speeches in the Riksdag’s debates. A low BLEU score may not necessarily imply the speaker is less intelligible for speech-to-text models, but may be the result of a combination of different factors:
- The official transcription may have taken less or more liberties when transcribing the speech.
- The segmentation (adjusted metadata) may have been systematically off for a particular speaker.
Interestingly, the vast majority of the bottom \(30\) list are men (\(28\) out of \(30\)). Many of the members of parliament on this list have thick accents, or speak in dialectal varieties of Swedish. The low BLEU scores either indicate that speech-to-text models perform worse for this subset, or that the official transcriptions tend to rephrase a lot of what was uttered.
The top \(30\) list, in contrast, seems to skew towards high BLEU scores for women (\(21\) out of \(30\)). An interesting research question to examine would be whether this to a higher degree can be attributed to the speech-to-text model, how transcriptions are written, or the degree to which speeches are prepared or improvised.
You can use the search feature on the Riksdag’s Web TV to search for debates these speakers participated in.
The speech finder method
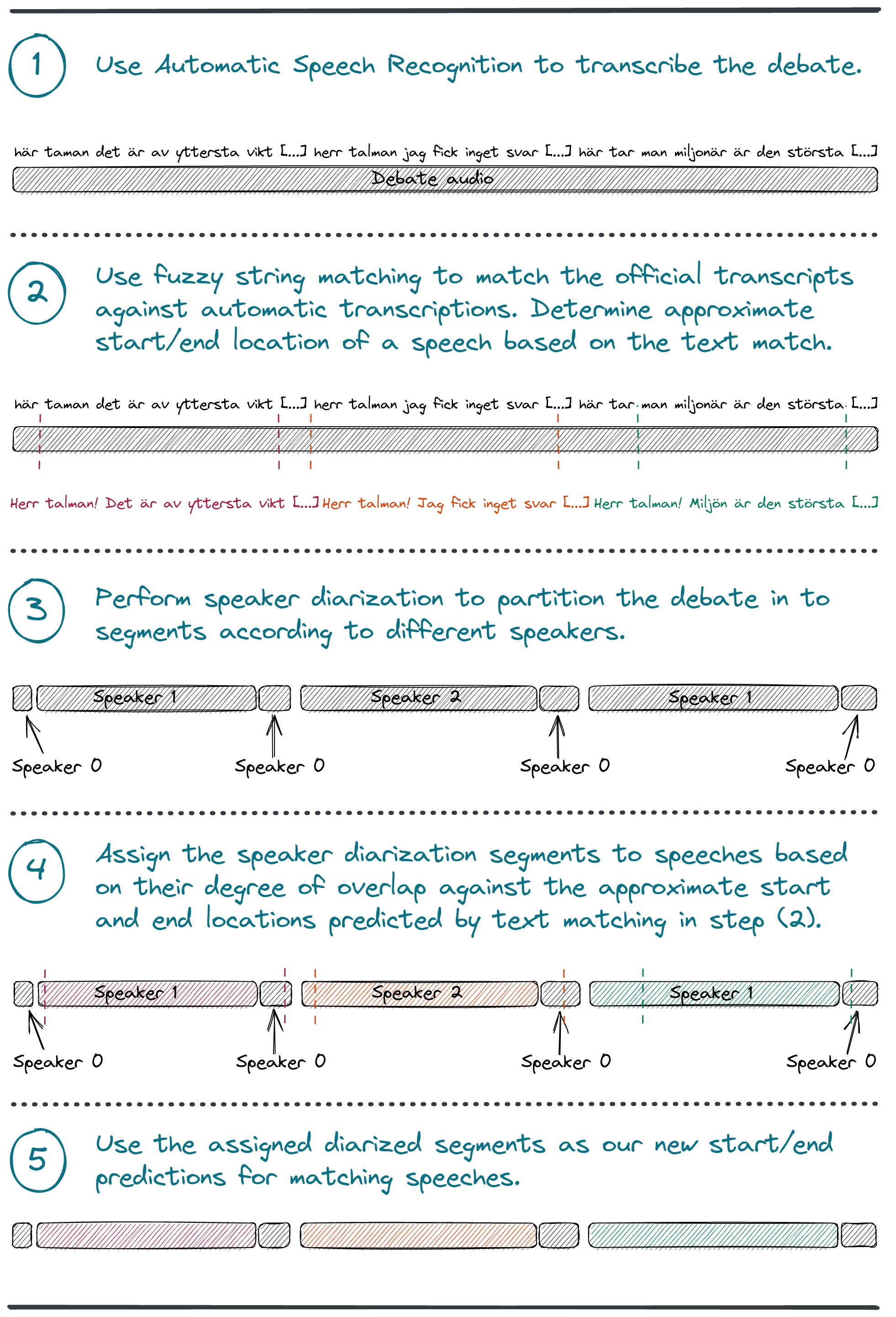
We’ll provide a short summary of our method here, since the concept is likely better illustrated in graphical form.
- We begin by using a speech-to-text model to transcribe an entire audio file. The speech-to-text model also outputs timestamps for when each of its output words were uttered. We use the model wav2vec2-large-voxrex-swedish (Malmsten et al. 2022).
- We use the official transcripts, and perform fuzzy string matching to locate what region of the automatic transcript they match against. The string matched region becomes an approximation of where the speech is located in the big audio file.
- We perform speaker diarization. This gives us a more detailed view of when different speakers spoke during the debate. We use the tool pyannote.audio (Bredin et al. 2020) (Bredin and Laurent 2021) for speaker diarization.
- We now still need to connect the speaker segments from the speaker diarization output to the official transcripts and the metadata associated with the transcripts. We therefore use the approximate predictions from the string matching method, and calculate the degre of overlap between different diarization speaker segments and the fuzzy string matched region of a speech.
- The dominant (most overlapping) speaker segment(s) becomes our prediction.
The idea is that this method should be completely independent way to generate speech segments – one that does not rely on the Riksdag’s already existing metadata. The only necessary components are i) a transcript, and ii) an audio file. The objective is essentially to find the needle (speech) in the haystack (audio file).
Evaluation of metadata quality
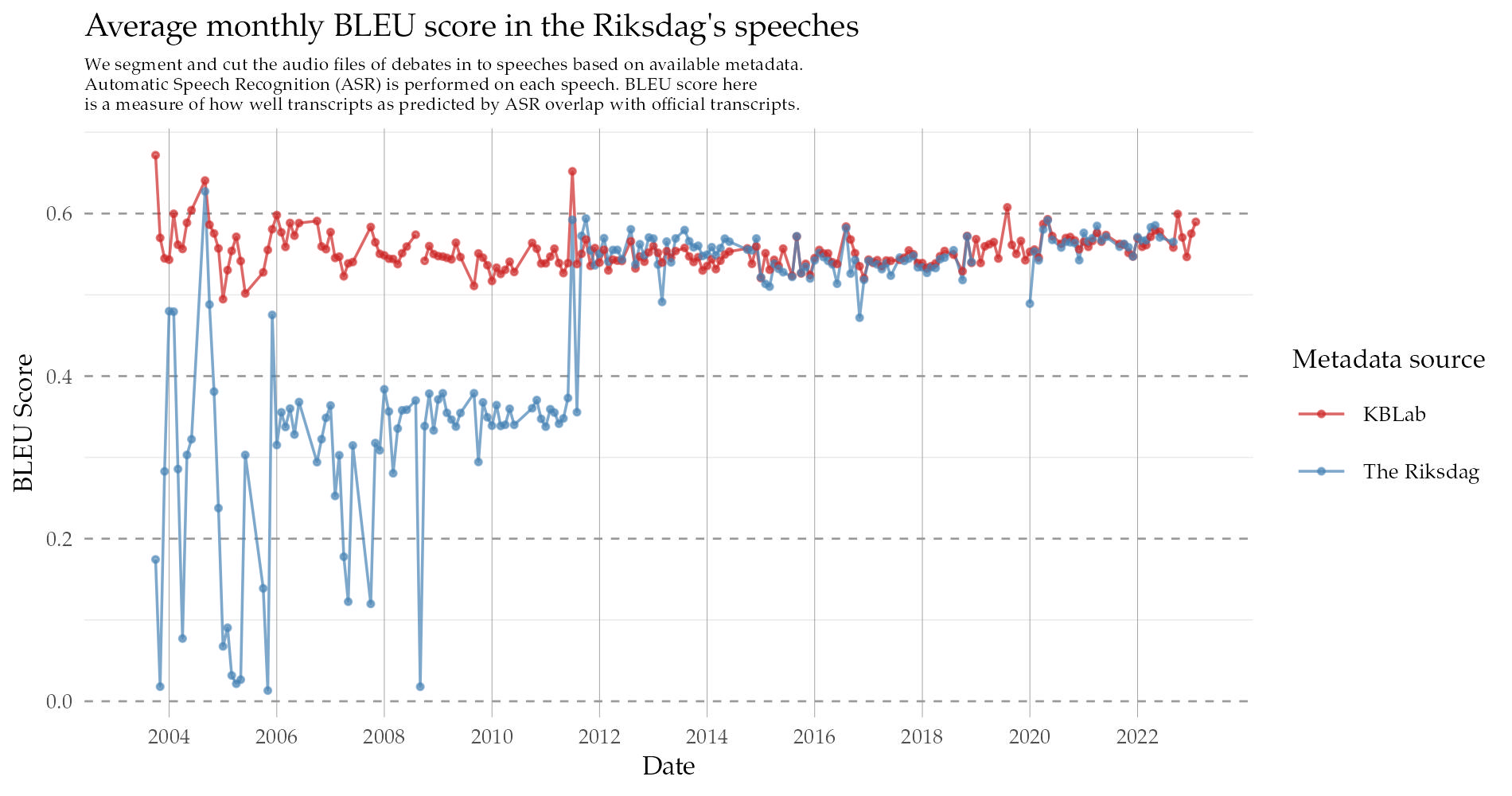
How do we know whether our method works or not? The benefit of the “speech finder” method being independent of the Riksdag’s official metadata, is that we can benchmark and compare against the portions of Riksdag data that maintain the best metadata quality. In general the best metadata quality is found in recent years, although most years since 2012 have had a fairly consistent and high quality.
In the plot below, we plot the average monthly BLEU scores over time (higher is better). KBLab’s adjusted metadata is of comparable quality the Riksdag’s metadata for, 2012 and forward. However, whereas the Riksdag’s BLEU scores drop for older debates, speech segmentations based on KBLabs adjusted metadata maintains an even and similar quality throughout the entire period.
The benefits of open data
We like open data at KBLab! The Riksdag’s open data is a wonderful resource that we believe will benefit research for many years to come. Making it easy for many people to acccess and use the Riksdag’s data creates positive spinoff effects. The WeStAc project with their curation of protocols from the Riksdag spanning back to the 1920s is one such example (see riksdagen-corpus). While KBLab’s primary objective in doing speech segmentation was to create an ASR dataset, the method and metadata output can be shared and used by both the Riksdag and other projects interested in curating Riksdag materials and possibly connecting curated protocols to audio and video recordings.
The audiovisual materials currently exposed in the Riksdag’s APIs has made it possible for us to create RixVox: a 5500 hour audio dataset with aligned text transcripts. From the point of view of KBLab, we benefit greatly from other organizations and research projects curating datasets, protocols and transcripts in this manner. We believe the method described in this article can likely successfully be applied to Riksdag debates from the 1960s to the 2000s. The prerequisite is simply having access to the audio, and a set of curated and well segmented textual transcripts from protocols. Luckily, since the Riksdag has done such a splendid job with their open data platform, there are research projects that have taken on the challenge!
Code and data
We plan on making RixVox, the 5500 hour speech-to-text dataset consisting of parliamentary speeches, freely and openly available on Huggingface. A new post will appear on this blog announcing the news when it is released!
The code for reproducing the speech segmentations, the adjusted metadata, and RixVox is available. See the Code and Data sections below.
Acknowledgements
Part of this development work was carried out within the frame of the infrastructural project HUMINFRA.

Code
The code for reproducing results in this article can be found on https://github.com/kb-labb/riksdagen_anforanden.
Data
The resulting metadata can be downloaded, and has been shared with the Riksdag. You can find the metadata here: https://github.com/kb-labb/riksdagen_anforanden/tree/main/metadata.
References
Bredin, Hervé, and Antoine Laurent. 2021. “End-to-end speaker segmentation for overlap-aware resegmentation.” Proc. Interspeech 2021.
Bredin, Hervé, Ruiqing Yin, Juan Manuel Coria, et al. 2020. “pyannote.audio: neural building blocks for speaker diarization.” ICASSP 2020, IEEE International Conference on Acoustics, Speech, and Signal Processing.
Malmsten, Martin, Chris Haffenden, and Love Börjeson. 2022. Hearing Voices at the National Library – a Speech Corpus and Acoustic Model for the Swedish Language. https://arxiv.org/abs/2205.03026.
Footnotes
An example can be seen here: https://www.riksdagen.se/sv/webb-tv/video/partiledardebatt/partiledardebatt_HAC120230118pd↩︎
The file Sagtochgjort.csv.zip here: https://data.riksdagen.se/data/ledamoter/↩︎
Citation
BibTeX citation:
@online{rekathati2023,
author = {Rekathati, Faton},
title = {Finding {Speeches} in the {Riksdag’s} {Debates}},
date = {2023-02-23},
url = {https://kb-labb.github.io/posts/2023-02-15-finding-speeches-in-the-riksdags-debates/},
langid = {en}
}
For attribution, please cite this work as:
Rekathati, Faton. 2023. “Finding Speeches in the Riksdag’s
Debates.” February 23. https://kb-labb.github.io/posts/2023-02-15-finding-speeches-in-the-riksdags-debates/.