Introduction
As more visual collections are digitised and the volume of born-digital material increases, libraries, archives and museums face a familiar challenge: images accumulate much faster than the metadata necessary to make them searchable. This creates huge amounts of material that remain difficult to navigate in practice. Without a sense of the themes running through a collection, it becomes hard to see what is present, how items relate to one another or where there might be gaps in description.
In this post, we introduce CLIP-Topic, a method for discovering thematic patterns in visual datasets using multimodal AI. The approach builds on OpenAI’s CLIP model and adapts topic-modelling techniques widely used in textual analysis. For institutions working with heterogeneous image collections lacking consistent metadata, CLIP-Topic provides a way to generate an initial thematic overview at scale.
Why bring topic modelling to images?
Topic modelling has proven valuable for exploring large text corpora, especially when combined with transformer-based models like BERT, e.g. BERTopic. Extending this idea to images has only recently become feasible. Unlike text, images contain overlapping motifs, stylistic cues and contextual details that resist easy segmentation, which makes large-scale thematic analysis challenging. This complexity is compounded by the fact that visual materials lack the structural cues that enable textual topic modelling, and image metadata is often inconsistent or minimal.
CLIP-Topic addresses this by using CLIP embeddings — vector representations that capture visual features alongside associated text. By clustering these embeddings, the method identifies groups of images with shared motifs. Provisional labels can then be generated using textual prompts, metadata or nearest-neighbour text embeddings (Grootendorst 2022).
The goal is not to produce definitive categories but to create a navigable thematic map of a collection.
What CLIP-Topic can reveal
In practical terms, CLIP-Topic helps surface patterns that are difficult to see manually, especially in large or loosely curated datasets:
Recurring visual themes, even when not reflected in the metadata.
Cross-collection links, where items from different sources share visual traits.
Overlooked motifs, particularly in collections lacking detailed description.
Structural absences, such as areas where images fail to cluster due to bias or limited representation.
Stylistic or temporal shifts, where clusters reveal changes in visual conventions or materials over time that might otherwise go unnoticed or remain undocumented.
For GLAM institutions, these insights can support tasks ranging from curatorial planning to collection assessment and research exploration. For researchers of visual heritage, these clusters offer a way to analyse large image corpora comparatively, trace thematic or stylistic patterns over time, and generate new questions about how visual material is organised and represented (Smits and Wevers 2023).
How the method works
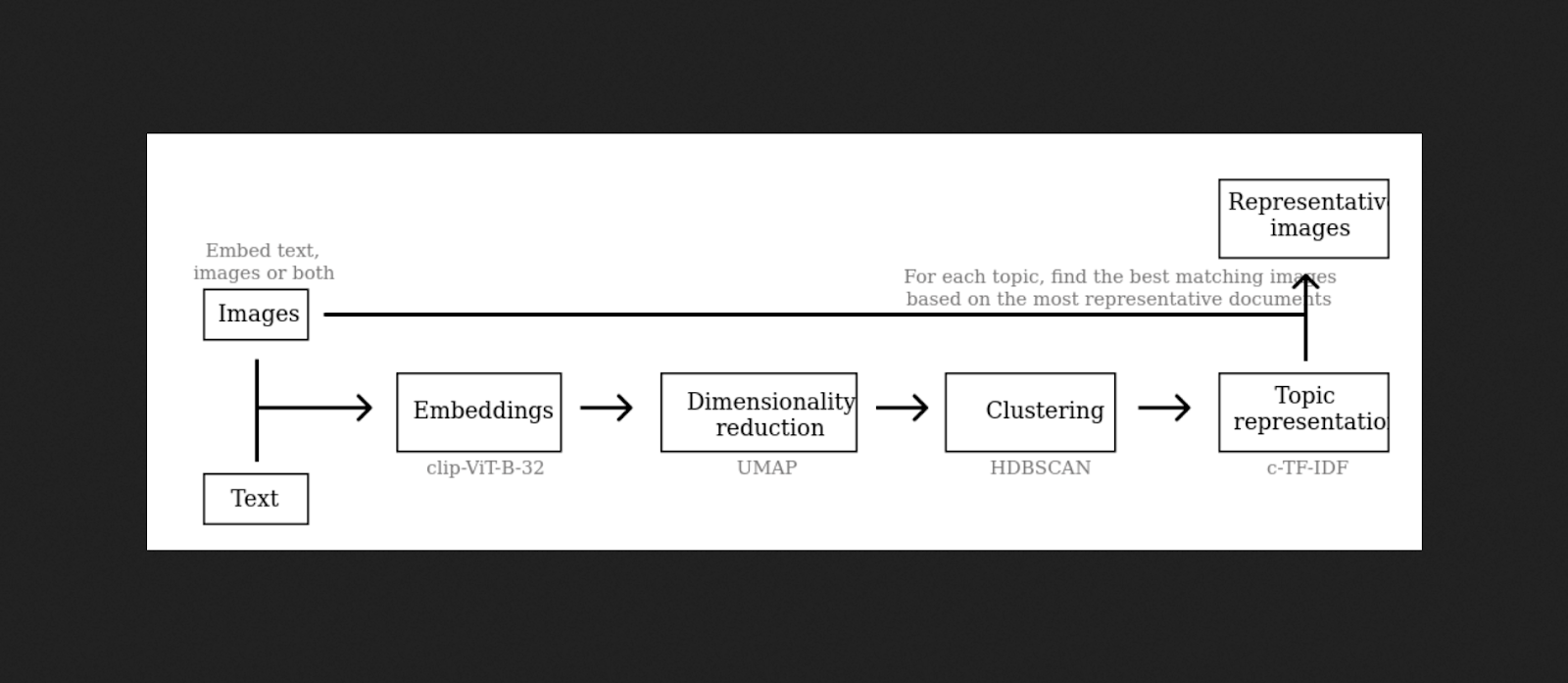
The workflow consists of four straightforward steps:
Embed the images. Each image is processed through a CLIP model to generate an embedding — a compact numerical representation that allows images to be compared computationally.
Cluster the embeddings. Algorithms such as HDBSCAN or k-means group similar images.
Generate labels. Representative words or phrases are produced using prompts, metadata, or text embeddings, giving each cluster a provisional “topic” label.
Interpret. Subject-matter expertise is essential for understanding what the clusters represent and how reliable the labels are.
Although the workflow is automated, human interpretation remains essential. The method suggests patterns; it does not decide their meaning. In our accompanying workshop (see the conclusion below), we demonstrate three parallel pathways — text-only, image-only and multimodal— to show how each signal behaves and what the combined approach contributes to interpretation.
A small experiment: postcards as a visual corpus
To explore the potential of CLIP-Topic, we recently applied it to a collection of historical postcards. Even in this modest experiment, the clustering surfaced clear thematic groups. One contained snowy cityscapes: winter streets, dark skies, and drifting snow rendered in different artistic styles (see Figure 1). Another grouped images of parades and military formations, bringing together items dispersed across the collection (see Figure 3). These clusters provided a fast way of seeing what kinds of motifs recur across thousands of images. For institutions with large quantities of under-labelled visual material, this offers a practical route to understanding a collection’s thematic range without requiring exhaustive manual work.


Limitations and considerations
Like all search methods that build upon current multimodal AI models, CLIP-Topic has constraints that it is important to recognize and adapt for.
Risk of anachronism. Because CLIP is trained on contemporary web data, it has a tendency to project modern associations onto historical images. This is not usually a problem for broad visual features, but it becomes more delicate when dealing with historically specific motifs. In one experiment, a cluster of church interiors and museum objects was labelled with terms including “skateboard” (see Figure 4) — a reminder of how training data shapes interpretation (Smits and Wevers 2023).
Metadata matters. Even though CLIP-Topic can cluster images purely on the basis of visual similarity, sparse or inconsistent textual descriptions limit the model’s ability to generate precise labels for those clusters. In such cases, the underlying groupings remain coherent, but the textual summaries may be generic or less helpful for interpretation.
Clusters are provisional. Themes may overlap or be internally diverse, and the level of granularity chosen for clustering directly shapes how specific—or how general—the resulting topics become. Coarser clustering can reveal broad patterns but may obscure meaningful variation, while finer clustering can surface particular motifs at the cost of producing a larger number of smaller, harder-to-interpret groups. For this reason, clusters should be treated as prompts for exploration rather than fixed categories. It is crucial not to treat the results as fixed, but to recognise how they might shift when the method’s parameters are adjusted.
These issues do not diminish the method’s value, but they underline the importance of expert review, contextual interpretation and attention to how different parameter choices shape the results. Such methodological self-reflexivity is essential.

Why this matters for GLAM institutions
Multimodal topic modelling broadens what is possible in large-scale visual analysis. It provides institutions with:
a rapid way to map the thematic contents of image collections
automated tagging that can feed into cataloguing and documentation workflows
new opportunities for discovery interfaces, research dashboards and visual search tools — like our CLIP-based image search demo
a foundation for linking images with related textual or audiovisual content
In combination with other machine-learning techniques — such as ASR for transcribing AV materials, e.g. KB-Whisper — CLIP-Topic can help create more coherent, interconnected heritage datasets.
Conclusion
CLIP-Topic does not replace archival description or curatorial expertise. What it offers is an additional layer of insight: a thematic overview that helps institutions understand large image collections more effectively, making it easier to identify recurring motifs and notice connections that may otherwise remain obscure.
As part of this work, we have also created an openly accessible Google Colab notebook designed to help users experiment with CLIP-Topic in a hands-on way. Developed within the national infrastructure Huminfra, the notebook introduces the method through a small, curated set of images from DigitaltMuseum and combines brief explanatory notes with runnable code cells. Because everything runs in the browser — no installation, no setup — it offers a low-barrier way of seeing how the workflow unfolds in practice. More importantly, it is meant to be revisited and adapted: the notebook can be explored at one’s own pace and reused with local collections, supporting both experimentation and understanding (Sikora 2024).
Check out the Google Colab notebook on CLIP-Topic
This post accompanies our poster for the AI4LAM Fantastic Futures 2025 conference hosted at the British Library. If you are interested in trying CLIP-Topic on your own collections, we invite you to explore the notebook and see what patterns emerge!
References
Acknowledgments
Part of this development work was carried out within the HUMINFRA infrastructure project.

Citation
@online{haffenden2025,
author = {Haffenden, Chris and Sikora, Justyna},
title = {CLIP-Topic: {Identifying} {Themes} in {Large} {Image}
{Collections}},
date = {2025-12-01},
url = {https://kb-labb.github.io/posts/2025-12-01-clip-topic/},
langid = {en}
}